Introduction
The release of GLM-4.5V undoubtedly marks another milestone in the field of multimodal AI. It not only achieves significant improvements in multimodal understanding and reasoning but also demonstrates strong performance and broad application potential through its unique architectural design, refined data construction, and application of reinforcement learning.

Performance
GLM-4.5V has significantly improved performance in multimodal understanding and reasoning compared to previous models.
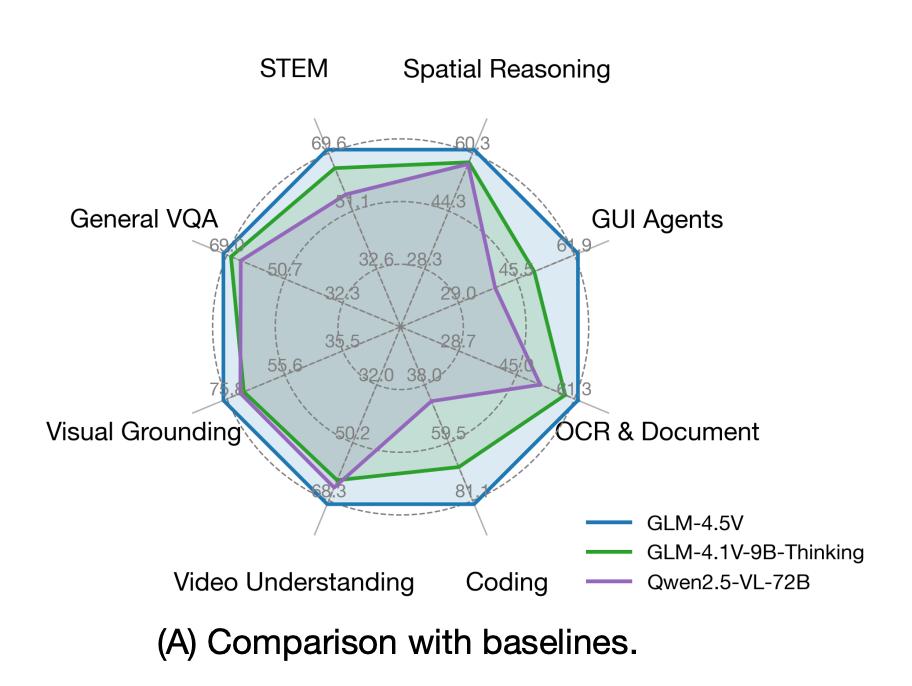
In the above chart, GLM-4.5V outperforms previous models in STEM, spatial reasoning, GUI agent tasks, OCR, document understanding, code comprehension, video understanding, visual localization, and general VQA tasks.
The backbone of GLM-4.5V is a reinforcement learning (RL) framework.
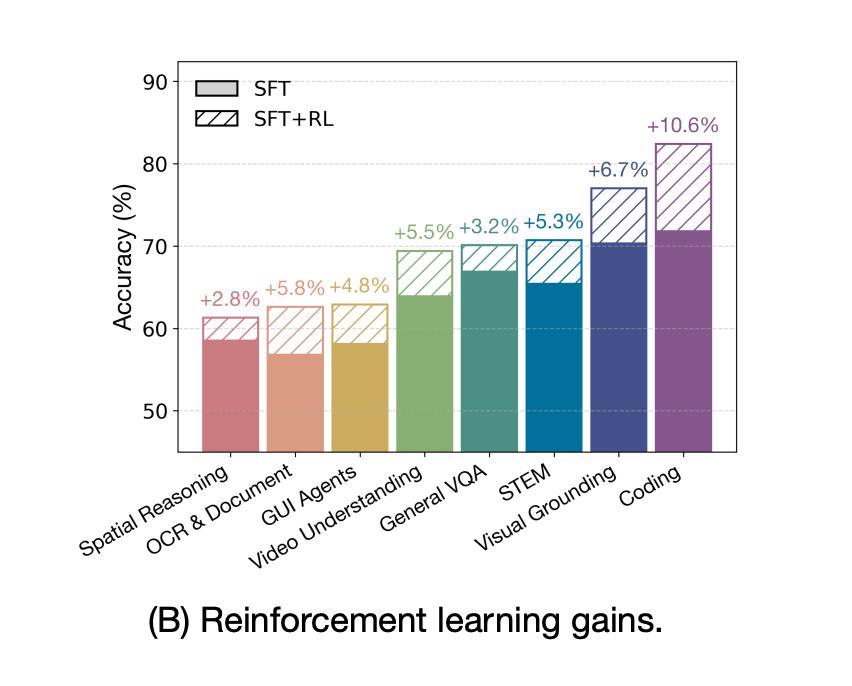
After reinforcement learning, the model achieved a gain of up to +10.6% in coding tasks and +6.7% in STEM questions.
GLM-4.5V achieved the best scores in nearly all high-difficulty tasks, including MMStar (75.3), MMMU Pro (65.2), MathVista (84.6), ChartQAPro (64.0), and WebVoyager (84.4).
Architecture
The architectural design of GLM-4.5V focuses on three goals: native multimodality, high resolution, and strong temporal understanding. This is achieved through three components: the visual encoder (ViT Encoder), MLP projector, and language decoder (LLM Decoder).
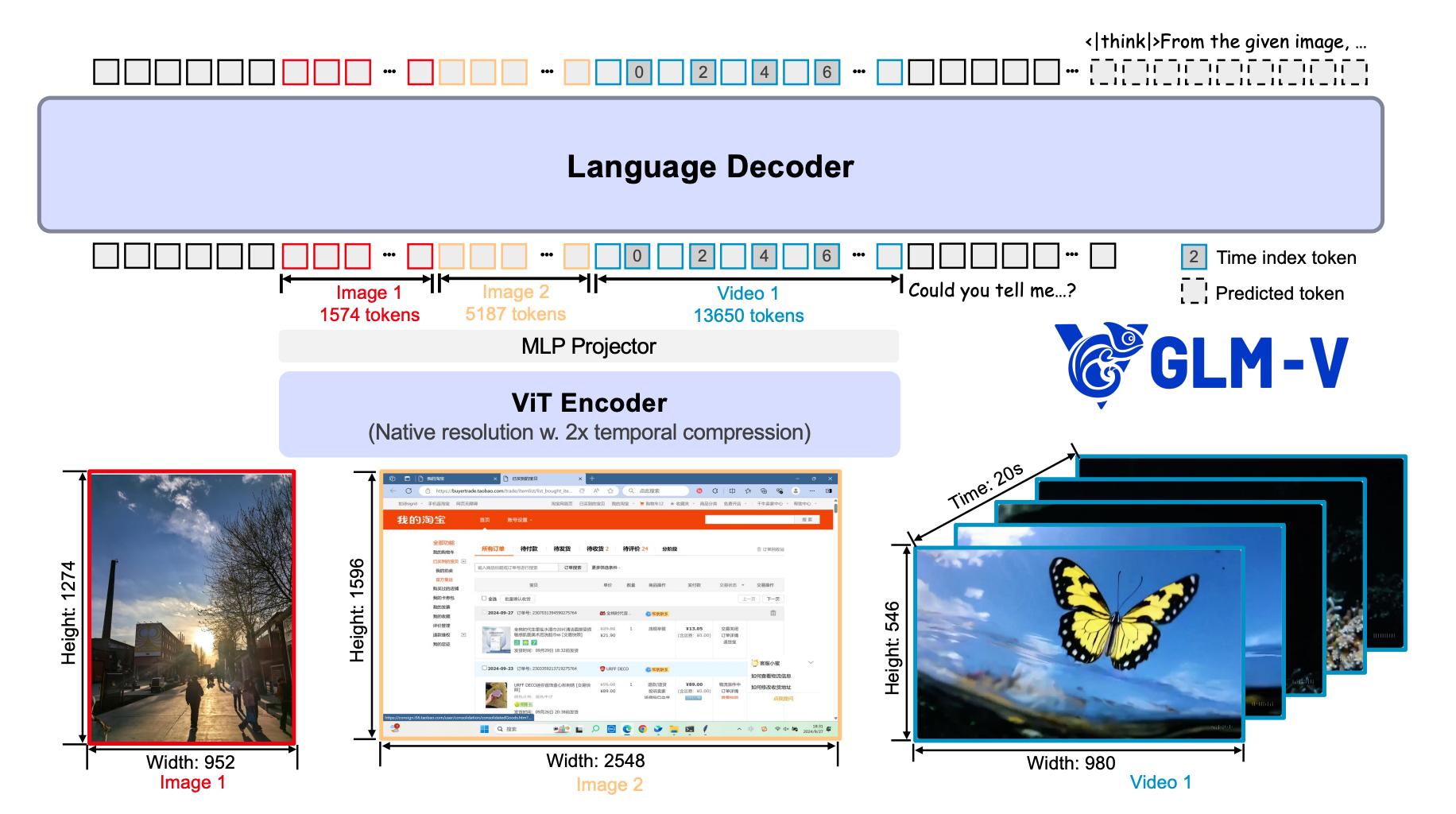
Visual Encoder
Based on AIMv2-Huge initialization, it incorporates 2D-ROPE and 3D convolutions, enabling it to natively process images and videos of any resolution while effectively capturing temporal information.
Language Decoder
Based on GLM-4.5-Air, it enhances the understanding of spatial positions in multimodal inputs by extending 3D-RoPE.
Native Temporal Understanding
When processing videos, the model inserts a timestamp token after the visual features of each frame, allowing it to perceive the actual time intervals between frames, greatly improving video understanding and localization accuracy.
Pre-training
The pre-training of GLM-4.5V consists of data construction and training paradigms.
Data Construction
The pre-training corpus of GLM-4.5V covers multidimensional data, including:
Image-Text Pair Data
Over 10 billion high-quality image-text pairs were constructed through a refined process involving heuristic filtering, CLIP-Score selection, concept-balanced resampling, and factual-centered recaptioning. Each image has a better rephrasing.
For example, a simple description like “a northern cardinal singing” can be enriched to “a northern cardinal perched on a branch with a clear blue sky in the background,” retaining the facts while greatly enhancing the detail and information density of the description.
Interleaved Image-Text Data
High-quality mixed content was extracted from web pages and academic books, allowing the model to learn complex logical relationships and domain knowledge.
OCR Data
A dataset of 220 million images was constructed, covering synthetic documents, natural scene text, and academic documents, significantly improving text recognition capabilities.
Grounding Data
A mixed grounding dataset was created, containing 40 million annotated natural images and over 140 million GUI question-answer pairs, providing the model with precise pixel-level understanding capabilities.
Video Data
A high-quality video dataset was constructed through meticulous manual annotation, capturing complex actions, scene text, and cinematic elements.
Training Paradigms: Two-Stage, Long Context
GLM-4.5V employs a two-stage training strategy:
Multimodal Pre-training
Training was conducted for 120,000 steps using all data except video at a sequence length of 8192.
Long Context Continuous Training: The sequence length was extended to 32,768, incorporating video data for an additional 10,000 steps of training, enabling the model to handle high-resolution images, long videos, and lengthy documents.
Post-training: SFT and RL
The post-training phase is crucial for enhancing the reasoning capabilities of GLM-4.5V, consisting of supervised fine-tuning (SFT) and reinforcement learning (RL) steps.
Supervised Fine-tuning (SFT): Aligning Thought Paradigms
The goal of SFT is to align the model’s thinking and expression style, teaching it to reason in the form of a “Chain-of-Thought.”
Standard Format
All training data follows the standard format
Answer Extraction: For tasks requiring precise answers, the final answer is wrapped in special tokens <|begin_of_box|> and <|end_of_box|> for accurate assessment by the subsequent RL phase’s reward model.
Dual-Modal Support: GLM-4.5V mixes “thinking” and “non-thinking” data during the SFT phase and introduces special token /nothink, achieving flexible switching between two reasoning modes, balancing performance and efficiency.
Reinforcement Learning (RL): Unlocking Model Potential
GLM-4.5V enhances reasoning capabilities through large-scale, cross-domain reinforcement learning.
RLCS Curriculum Learning Sampling
To improve training efficiency, the team proposed Reinforcement Learning with Curriculum Sampling (RLCS), which dynamically selects moderately difficult training samples based on the model’s current abilities, avoiding wasted computational power on overly easy or difficult problems, thus maximizing the benefits of each training step.
Robust Reward System
The success of RL largely depends on the quality of the reward signals. GLM-4.5V established a domain-specific reward system, designing specialized validation logic for tasks like math, OCR, and GUI, avoiding the phenomenon of “reward hacking.”
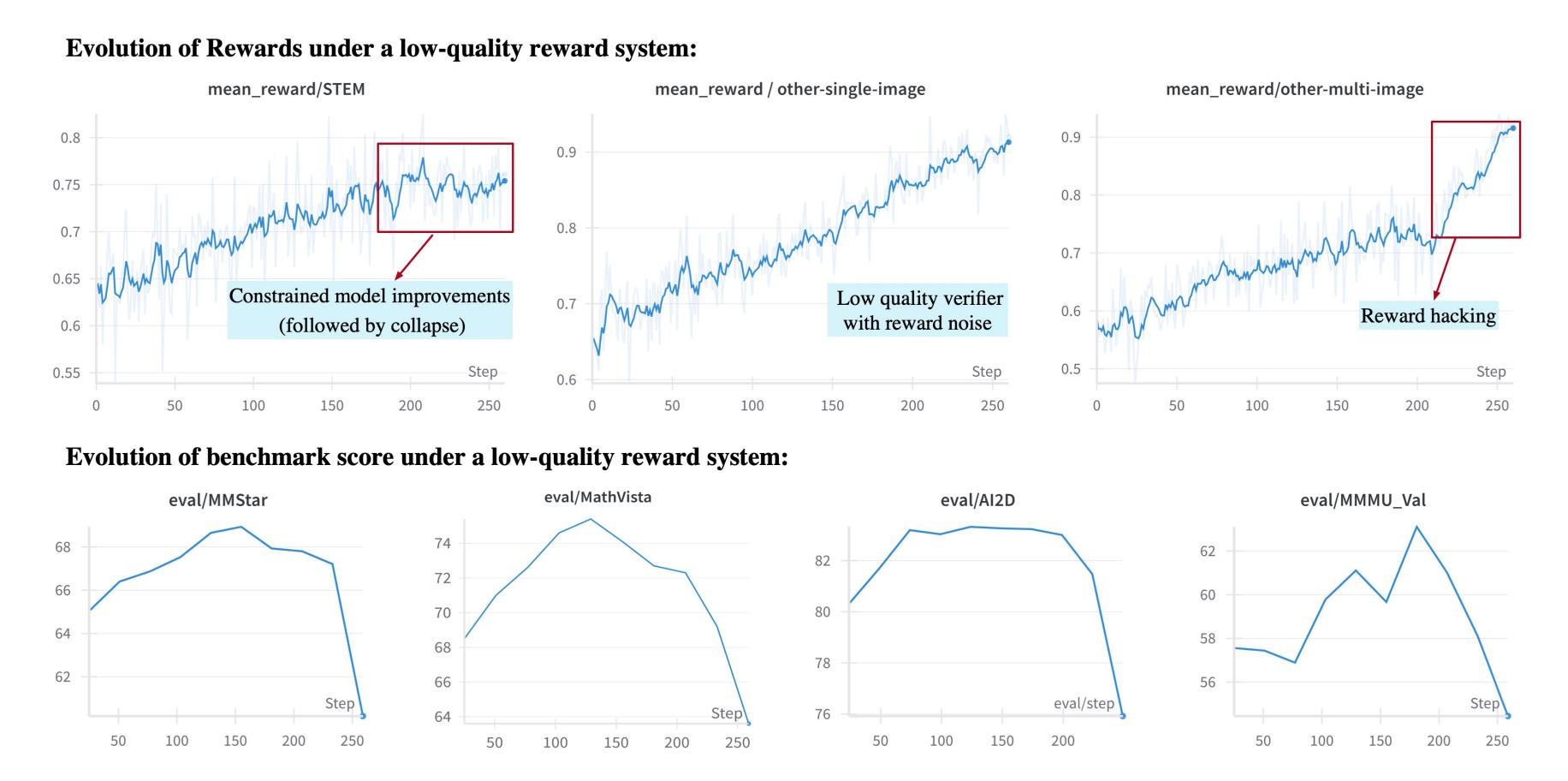
As shown in the above image, even with high-quality reward signals in the STEM field, a defective reward model in a multi-image VQA task can lead to a complete collapse of the entire training process after 150 steps.
This indicates that any shortcoming can become a critical issue, particularly for RL training.
Cross-domain generalization and collaborative RL not only enhance the model’s capabilities in specific domains but also yield significant cross-domain generalization effects.
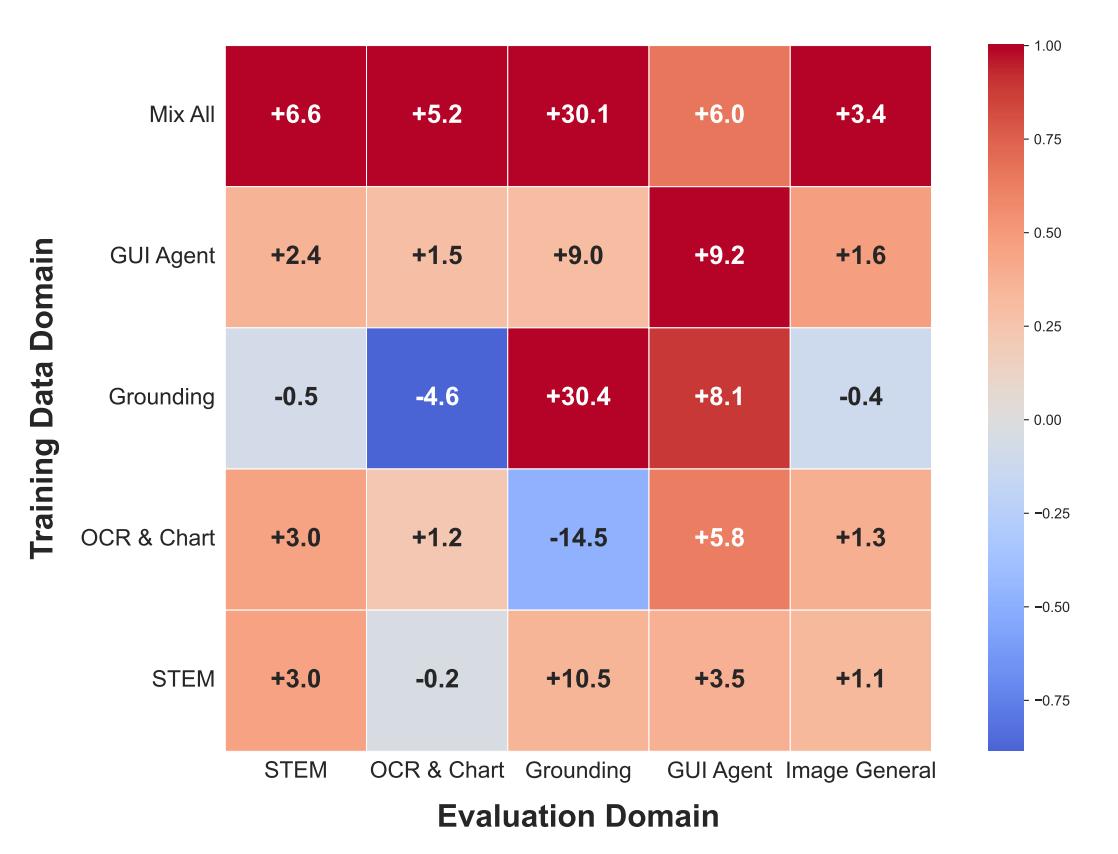
As illustrated, training in a single domain can improve capabilities in other domains. For example, training solely on GUI agent data can boost performance in STEM, OCR, visual localization, and general VQA tasks.
This suggests that there is a shared underlying logic among different multimodal capabilities, and mixing all domain data for training can achieve stronger results than single-domain training, realizing a synergistic effect of “1+1 > 2.”
Conclusion
The training of GLM-4.5V encompasses:
- Architecture: Native support for high resolution, long videos, and temporal understanding.
- Pre-training: Refined data construction and two-stage training.
- SFT: Aligning the model with the “Chain-of-Thought” reasoning paradigm, preparing for the RL phase.
- RL: Enhancing capabilities through RLCS, a robust reward system, and cross-domain training.
Stay tuned for the upcoming GLM-4.5V-355B.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.