Ten Fundamental Challenges AI Has Yet to Solve
Recently, two graphs have been circulating widely in the AI community, showcasing OpenAI’s exponential leap forward. The charts from Artificial Analysis clearly indicate that OpenAI is continuously improving over time, with the effects of rapid iteration and exponential growth becoming evident.
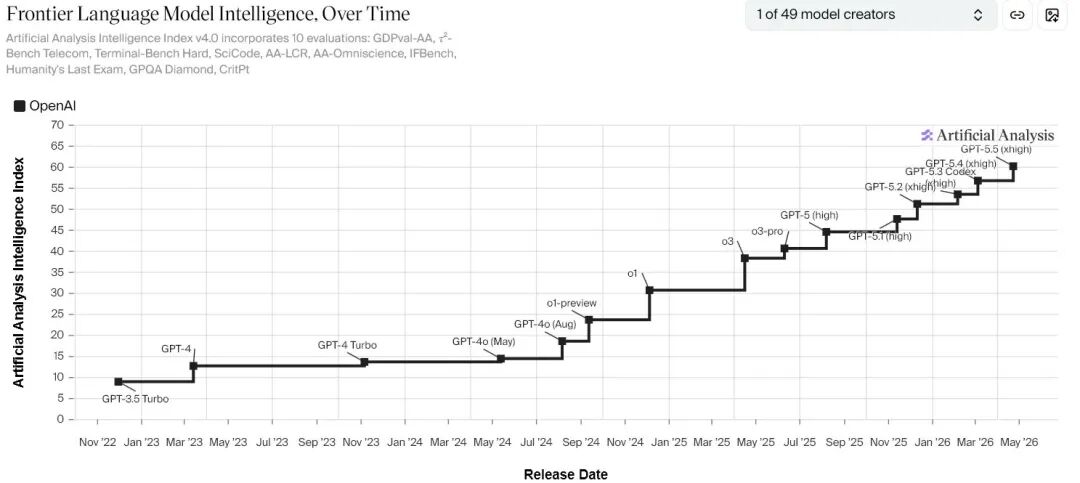
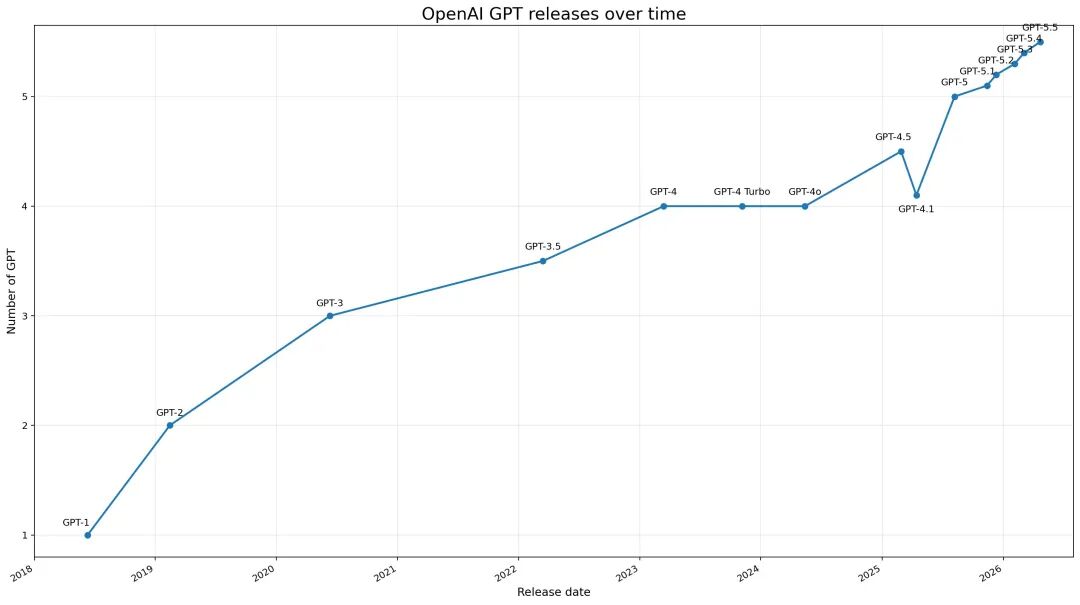
Another chart detailing the release timeline of GPT shows that the singularity is drawing near, with no signs of a slowdown in the growth curve—each new node surpassing the previous one.
However, beneath this thrilling commercial narrative, I must reiterate my previous assessment: what are the capability boundaries of large language models (LLMs)? At the end of language, we rediscover the future of humanity. The current paradigm of large language models not only has capability boundaries but also faces numerous unresolved challenges:
-
Causal Understanding: AI can recognize correlations, but when will it truly understand “why”? Most large models fundamentally learn “what often occurs together” within statistical co-occurrence structures. This supports impressive language capabilities but does not automatically lead to causal understanding. Without causal comprehension, models struggle to perform robustly in counterfactual reasoning, policy interventions, medical decision-making, scientific discoveries, and complex planning. Recent research on LLMs’ causal inference abilities is still grappling with a basic question: can these models reliably identify causal relationships under conditions close to the complexity of real text?
-
World Models and Common Sense: Why do language models still not “truly live in the world”? A clear trend in recent years is that top AI labs are converging towards world models and embodied AI. Google DeepMind officially launched Genie 3 in 2025, explicitly calling it “a new frontier for world models”. This indicates that the mainstream industry view is not that “pure language scaling is sufficient,” but rather that “models still lack intrinsic representations of the physical world, spatial structures, temporal continuity, and action consequences”.
-
Long-Term Planning and Autonomy: Being able to chat does not equate to long-term action. Today’s models can invoke tools, decompose tasks, write code, control browsers, and even exhibit primitive agent behavior. However, a significant gap remains between “completing a task” and “working autonomously and stably in an open environment over the long term”. A true agent requires goal maintenance, error recovery, resource allocation, memory updating, environmental modeling, risk assessment, and multi-step planning—abilities that are currently still quite weak.
-
Continual Learning: Why can’t AI learn like humans do, “learning while using”? One of the strongest aspects of the human brain is its ability to learn continuously in a changing environment without completely forgetting old knowledge. This remains a weak point for current AI. Reviews on continual learning repeatedly point out that artificial neural networks easily suffer from catastrophic forgetting during sequential learning. Google Research’s nested learning concept proposed in 2025 acknowledges that “updating models with new data often quickly sacrifices old capabilities”.
-
Explainability: We still do not know why models “think” the way they do. As model capabilities increase, the “black box” problem becomes more pronounced. ACM reviews state that LLM explainability has developed into an independent research direction due to the complexity of their internal mechanisms, which traditional explanatory frameworks struggle to cover. This means that while we can observe many impressive behaviors, we still find it challenging to answer: what concepts, circuits, or strategies have formed internally?
-
Alignment and Control: How can we ensure that more powerful models still work in the direction humans want? The stronger the capability, the more pressing the alignment issue becomes. The 2026 International AI Safety Report and Google DeepMind’s updated Frontier Safety Framework emphasize that the serious risks of cutting-edge models arise not just from errors but also from more complex combinations of capabilities, such as strategic behavior, tool enhancement, dangerous knowledge diffusion, and safety claims that are difficult to independently verify.
-
Evaluation: Are our current benchmarks truly measuring “intelligence”? The 2026 Stanford HAI AI Index report indicates that leading models are increasingly indistinguishable from each other, and open-source models are rapidly closing the gap. While this may seem like “everyone is getting stronger,” it also means that traditional benchmarks are becoming increasingly ineffective at distinguishing true capability differences.
-
Reliability: Large models do not simply “occasionally answer a question incorrectly”; they generate non-existent facts, literature, legal bases, or reasoning chains under the guise of fluent and reasonable language. Reviews identify hallucination as a core obstacle for LLMs in real deployments.
-
Reasoning: Large models have indeed improved significantly in mathematics, coding, theorem proving, and multi-step tasks, but “strong” does not equate to “solved”. Research from Apple in 2025 pointed out that cutting-edge reasoning models experience accuracy collapse on increasingly complex tasks and exhibit a counterintuitive phenomenon: the more complex the problem, the less effort the model invests in reasoning.
-
Efficiency Boundaries: Does stronger AI necessarily come at the cost of higher computational power and energy consumption? In recent years, the main theme of AI has been “larger data, larger models, larger computational power.” However, this path is increasingly constrained by reality. The 2026 Stanford AI Index and multiple energy studies indicate that the training and inference of cutting-edge AI are driving up infrastructure demands.
Conclusion
Today’s AI has yet to thoroughly resolve core issues that truly define advanced intelligence, such as reliable understanding, continual learning, causal modeling, long-term action, internal explainability, and external control. Therefore, even with the recent release of GPT-5.5 and a renewed industry enthusiasm, my assessment remains that we are in a phase where “capability explosion” coexists with “unclear principles.” Future breakthroughs in the next decade are unlikely to come merely from scaling models but are more likely to arise from tackling these underlying unresolved challenges.
Comments
Discussion is powered by Giscus (GitHub Discussions). Add
repo,repoID,category, andcategoryIDunder[params.comments.giscus]inhugo.tomlusing the values from the Giscus setup tool.